Motivação
Há um tempo atrás eu comecei a pensar em trocar o apartamento em que moro por um maior, dado toda a questão da pandemia, home office e o aumento no tamanho da família. Logo, comecei a buscar as opções disponíveis aqui em Niterói, mas me deparei com algumas dúvidas:
- Quanto vale o apartamento em que morava? Dado que eu faria uma troca, eu precisava saber o quanto ele deve valer para saber até onde eu poderia buscar.
- Como saber se um apartamento está anunciado a um preço razoável? Isto é, como eu poderia saber se o valor que estavam pedindo por uma apartamento está dentro do valor de mercado, acima ou abaixo dele? Ter acesso à essa informação é importante também para avaliar quão boa uma oportunidade de fato é.
Com isso em mente, tive a ideia de pegar todas informações que podia obter de anúncios sobre o preço dos apartamentos, suas características, localização geográfica e tudo mais e utilizar algum algoritmo de Machine Learning para me ajudar (1) à prever o valor de um apartamento baseado nestas informações e (2) definir se o valor anunciado era um valor razoável ou não. Quanto a este último ponto, eu poderia até ir além: caso o valor anunciado estivesse abaixo daquele previsto pelo modelo utilizado, então possivelmente o apartamento estava sendo vendido abaixo do valor de mercado e, portanto, poderia ser um potencial bom negócio.
Seguindo esta ideia, raspei o site do ZapImóveis atrás de todos os anúncios de apartamentos à venda no município de Niterói/RJ no início de mês de agosto. Eu organizei os dados coletados, selecionei algumas informações primárias para me ajudar nesta tarefa e, aqui neste post, eu busco entender estes dados e fazer uso deles para me ajudar a obter as respostas que estava buscando para as perguntas feitas originalmente.
Descrição dos Dados
Vamos começar carregando os dados obtidos através do ZapImóveis, e já passados por um processo prévio de faxina (que eu não apresento aqui).
Show code
# carregando os pacotes necessários
library(tidyverse) # manipulação de dados
library(skimr) # diagnostico rapido da base
library(reactable) # facilita a visualização de tabelas
library(sf) # mapas
# carregando os dados dos anuncios já tratados e limpos
dados <- read_rds(file = 'data/base_analitica.rds')
# carregando o shapefile de niteroi
niteroi <- read_sf('data/bairros_niteroi.shp')
# visao geral dos dados
skim_without_charts(data = dados) %>%
as_tibble() %>%
select(skim_type:complete_rate, character.n_unique, contains('numeric')) %>%
reactable(striped = TRUE, highlight = TRUE, compact = TRUE, showSortable = TRUE,
style = list(fontSize = "12px"),
defaultColDef = colDef(align = 'center'),
columns = list(
skim_type = colDef(name = 'Tipo'),
skim_variable = colDef(name = 'Variável'),
n_missing = colDef(name = 'Qtd. Faltantes'),
complete_rate = colDef(name = 'Prop. Completa', format = colFormat(digits = 2)),
character.n_unique = colDef(name = 'Níveis Únicos'),
numeric.mean = colDef(name = 'Média', format = colFormat(digits = 0)),
numeric.sd = colDef(name = 'Desvio Padrão', format = colFormat(digits = 0)),
numeric.p0 = colDef(name = 'Mínimo', format = colFormat(digits = 0)),
numeric.p25 = colDef(name = 'Q25', format = colFormat(digits = 0)),
numeric.p50 = colDef(name = 'Mediana', format = colFormat(digits = 0)),
numeric.p75 = colDef(name = 'Q75', format = colFormat(digits = 0)),
numeric.p100 = colDef(name = 'Máximo', format = colFormat(digits = 0)))
)
A base carregada contém um total de 11.106 anúncios de apartamentos (apenas apartamentos, não busquei casas ou outros tipos de imóveis) situados no município de Niterói/RJ. Apesar da base completa possuir cerca de 300 colunas com informações extremamente detalhadas de cada imóvel, escolhi aqui trabalhar com um subconjunto muito menor de informações, no intuito de começar simples. Ainda assim, muitas das informações presentes nesta base já têm o potencial de fornecer insights importantes para a finalidade desta análise, tais como a quantidade de suítes, banheiros, quartos, vagas de garagem e área de cada apartamento. Além disso, possuímos informações de alto nível sobre a localização de cada imóvel, sendo importante notar que1:
- Niterói é composto por 52 bairros: Badu, Bairro de Fatima, Baldeador, Barreto, Boa Viagem, Cachoeiras, Cafuba, Camboinhas, Cantagalo, Caramujo, Centro, Charitas, Cubango, Engenho do Mato, Engenhoca, Fonseca, Gragoata, Icarai, Ilha da Conceição, Inga, Itacoatiara, Itaipu, Ititioca, Jacare, Jardim Imbui, Jurujuba, Largo da Batalha, Maceio, Maravista, Maria Paula, Matapaca, Morro do Estado, Muriqui, Pe Pequeno, Piratininga, Ponta D’Areia, Rio do Ouro, Santa Barbara, Santa Rosa, Santana, Santo Antonio, Sao Domingos, Sao Francisco, Sao Lourenco, Sape, Serra Grande, Tenente Jardim, Varzea das Mocas, Vicoso Jardim, Vila Progresso, Viradouro e Vital Brazil.
- Estes bairros estão organizados entre 19 sub-regiões administrativas (i.e., coluna Zona na base carregada), que tendem a agregar bairros adjacentes e, de certa forma, mais similares entre si: Barreto, Caramujo, Centro, Engenho do Mato, Engenhoca, Fonseca, Icarai, Itaipu, Ititioca, Jacare, Jurujuba, Largo da Batalha, Maravista, Piratininga, Rio do Ouro, Santa Rosa, Sao Francisco, Varzea das Mocas e Vila Progresso.
- Por sua vez, estas sub-regiões estão organizadas entre de 5 regiões administrativas, sendo elas: Leste, Norte, Oceanica, Pendotiba e Praias da Baia.
Todas estas informações sobre a organização político-administrativa de Niterói podem ser melhor visualizadas através do mapa abaixo2.
Show code
# carregando o leaflet
library(leaflet) # mapas interativos
# criando a paleta de cores
paleta_1 <- colorFactor(palette = 'inferno', domain = NULL, levels = sort(unique(niteroi$Regiao)))
# plotando o preco medio por Zona Administrativa
leaflet(niteroi) %>%
addPolygons(
popup = paste0(
'<b>Região Administrativa:</b> ', niteroi$Regiao, '<br>',
'<b>Sub-Região Administrativa:</b> ', niteroi$Zona, '<br>',
'<b>Bairro:</b> ', niteroi$Bairro, '<br>'
),
fillColor = ~ paleta_1(niteroi$Regiao),
fillOpacity = 0.6, smoothFactor = 0.5, weight = 0.8, color = 'black') %>%
addTiles()
Análise Exploratória
Conforme pôde ser visto na tabela de descrição da base, as únicas informações faltantes existentes estão nas colunas de latitude e longitude. Neste contexto, vamos começar olhando a distribuição espacial da nossa variável resposta, o preço do apartamento, através do bairro ao qual pertence o apartamento do anúncio.
O mapa abaixo mostra que o preço médio dos apartamentos parece ser maior nos bairros na porção sul e sudoeste do município (Charitas, São Francisco, Icaraí e Camboinhas, por exemplo). Além disso, podemos ver que não existem apartamentos à venda em alguns bairros (polígonos brancos no mapa abaixo). Todos esses padrões são bastante consistentes com o desenvolvimento do município, onde a construção civil tem avançado bastante rápido em alguns daqueles primeiros bairros. Uma informação importante, implícita no mapa, é que o preço médio dos apartamentos parece ser muito similar entre as regiões administrativas Norte, Pendotiba e Leste, e menores do que aquele observado nas regiões Oceânica e Praias da Baia. Além disso, note que a variância nos preços entre os bairros de uma região administrativa também parece ser menor para àquelas três primeiras regiões, e maior nas duas últimas. Isto será bastante importante quando formos preparar os dados para a modelagem.
Show code
# calculando preco medio por zona
preco_por_bairro <- dados %>%
group_by(neighborhood) %>%
summarise(preco_medio = mean(price)) %>%
left_join(x = niteroi, y = ., by = c('Bairro' = 'neighborhood'))
# criando a paleta de cores
paleta_2 <- colorNumeric(palette = 'viridis', domain = NULL, na.color = '#FFFFFF')
# plotando o preco medio por Bairro
leaflet(preco_por_bairro) %>%
addPolygons(
popup = paste0(
'<b>Região Administrativa:</b> ', preco_por_bairro$Regiao, '<br>',
'<b>Sub-Região Administrativa:</b> ', preco_por_bairro$Zona, '<br>',
'<b>Bairro:</b> ', preco_por_bairro$Bairro, '<br>',
'<b>Preço Médio:</b> ', scales::dollar(x = preco_por_bairro$preco_medio,
prefix = 'R$ ',
big.mark = '.',
decimal.mark = ',')
),
fillColor = ~ paleta_2(preco_por_bairro$preco_medio),
fillOpacity = 0.8, smoothFactor = 0.5, weight = 0.8, color = 'black') %>%
addTiles() %>%
addLegend(
title = 'Preço Médio do<br>Apartamento', position = 'bottomright', pal = paleta_2,
values = ~ preco_por_bairro$preco_medio, bins = 4, opacity = 0.8,
labFormat = labelFormat(prefix = 'R$ ', big.mark = '.')
)
Um segundo ponto importante a se notar é que 83.6% dos anúncios que serão analisados pertencem às sub-regiões de Icaraí, São Francisco, Santa Rosa e Centro - todas elas situadas na região administrativa ‘Praias da Baia,’ conforme podemos observar na figura acima. Ainda assim, parece existir um forte viés em favor de anúncios no bairro de Icaraí que, sozinho, representa cerca de 50% dos anúncios na base.
Show code
# quantidade de anuncios entre regioes e sub-regioes administrativas
dados %>%
count(Regiao, Zona) %>%
mutate(proporcao = n / sum(n)) %>%
ggplot(mapping = aes(x = reorder(Zona, -n), y = n, fill = Regiao)) +
geom_col(color = 'black', width = 0.7, size = 0.3, show.legend = FALSE) +
geom_text(mapping = aes(label = scales::percent(x = proporcao, accuracy = 0.01)), nudge_y = 200, size = 2) +
scale_fill_viridis_d(option = 'B', begin = 0.1, end = 0.9) +
labs(
title = "Os anúncios estão concentrados entre as sub-regiões administrativas da região 'Praias da Baia'",
x = 'Sub-Região Administrativa',
y = 'Quantidade de Anúncios'
) +
theme(
axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5)
)
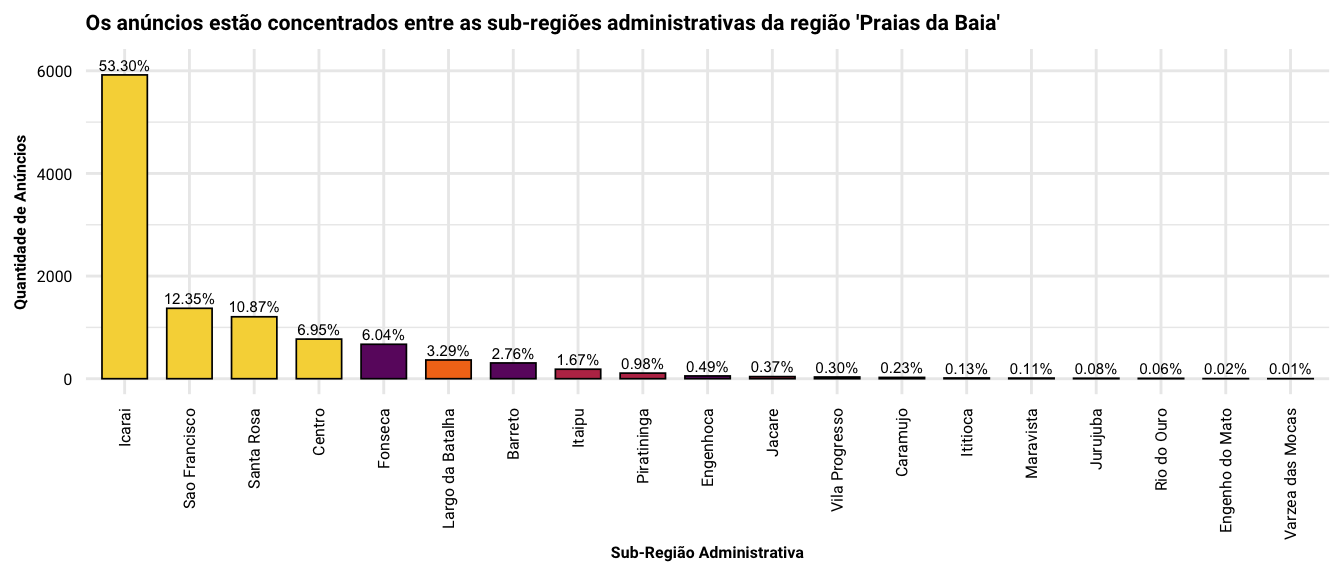
De fato, a figura abaixo demonstra que para cada 55 anúncios pertencentes ao bairro de Icaraí, temos 7 anúncios no bairro de Charitas, 3 anúncios no bairro do Ingá e 1 anúncio no bairro Vital Brazil (a quantidade de casinhas para cada bairro representa a proporção relativa de anúncios entre bairros). Em resumo, (a) a região administrativa das ‘Praias da Baia’ está sobre-representada na base analisada, (b) alguns poucos bairros fornecem praticamente toda a informação disponível na base e (c) nem todos os bairros de Niterói estão representados dentro desta base de dados. Ests três pedaços de informação serão importantes na hora em que formos preparar o modelo preditivo.
Show code
library(waffle) # para o waffle plot
# representatividade dos anuncios por bairro
dados %>%
mutate(Bairro = fct_lump_prop(f = neighborhood, prop = 0.01, other_level = 'Outros')) %>%
count(Bairro) %>%
mutate(
prop = n / 100
) %>%
ggplot(mapping = aes(label = Bairro, values = prop)) +
geom_pictogram(n_rows = 15, mapping = aes(color = Bairro),
make_proportional = FALSE, flip = TRUE, size = 5) +
scale_color_viridis_d(begin = 0.1) +
scale_label_pictogram(values = 'home') +
coord_equal() +
labs(
title = 'Razão relativa da quantidade de anúncios entre bairros',
subtitle = '99% dos anúncios na base estão associados a estes 10 bairros, ainda que Icaraí contribua com 49.7% deste total',
caption = "Cada casa representa cerca de 100 anúncios associadas à cada bairro.\nA categoria 'Outros' representa o somatório dos anúncios de todos os outros 32 bairros na base analisada."
) +
guides(color = guide_legend(title.vjust = 3, title.hjust = 0.3,
title.theme = element_text(face = 'bold', size = 8),
override.aes = list(size = 4))) +
theme_void(base_family = 'Roboto') +
theme(
plot.title = element_text(face = 'bold', size = 10),
plot.subtitle = element_text(size = 8),
plot.caption = element_text(size = 8)
)

A tabela de descrição dos dados logo no início deste post também apresenta mais uma curiosidade sobre quatro variáveis preditoras que estão na base…
- Parece não existir custo de condomínio para alguns apartamentos, enquanto outros informam um custo mensal que chega ao valor do próprio apartamento (painel a, abaixo). Me parece que este último caso representa algum tipo de erro de imputação de dados, enquanto o primeiro seria uma falha em reportar o valor real. Em todo caso, acredito que não dê para confiar tanto nessa informação, e vou ter que cuidar disso durante a preparação dos dados;
- Outra coisa curiosa está no próprio tamanho dos apartamentos (painel b): existem alguns apartamento bem pequenos (kitnets, talvez?), mas o que impressiona é pensar que existem apartamentos anunciados que vão do tamanho de campos de futebol de salão (uns 500m²) à campos de tamanho oficial (próximo à 6.000m²). Como acredito ser surreal que um apartamento seja tão grande assim, e é capaz que isto também seja um erro na base;
- Por fim, dois fatos curiosos estão nas variáveis de quantidade de banheiros (painel c) e vagas disponíveis (painel d). Existem anúncios que tratam de apartamentos com um número absurdo de banheiros (11 banheiros, sério?) e outros no qual uma única unidade parece ter disponível 8 vagas de garagem (haja carro ou espaço no prédio!). Nestes dois casos, acredito que estes valores tratam-se de erros de imputação de dados também.
Show code
library(patchwork) # para fazer uma composição de figuras
# distribuição da variável valor do condominio
p1 <- ggplot(data = dados, mapping = aes(x = monthlyCondoFee)) +
geom_density(size = 0.3) +
geom_rug(size = 0.3) +
scale_x_continuous(trans = 'log1p',
breaks = c(0, 10, 100, 3000, 50000, 600000),
labels = scales::dollar_format(
big.mark = '.', decimal.mark = ',', prefix = 'R$ ')
) +
labs(
x = 'Valor Mensal do Condomínio',
y = 'Densidade',
subtitle = '...condomínios grátis ou ao preço de um apartamento (por mês)\nsão um tanto estranho, não?'
)
# distribuição da variável área do apartamento
p2 <- ggplot(data = dados, mapping = aes(x = usableAreas)) +
geom_density(size = 0.3) +
geom_rug(size = 0.3) +
scale_x_continuous(trans = 'log1p',
breaks = c(10, 40, 90, 200, 500, 2000, 6000),
labels = scales::label_number(
big.mark = '.', decimal.mark = ',', suffix = ' m²')
) +
labs(
x = 'Área do Apartamento',
y = 'Densidade',
subtitle = '...apartamentos pequenos até são comuns atualmente, mas do tamanho\nde campos de futebol fazem sentido?'
)
# distribuição da variável quantidade de banheiros
p3 <- ggplot(data = dados, mapping = aes(x = bathrooms)) +
geom_density(size = 0.3) +
geom_rug(size = 0.3) +
scale_x_continuous(breaks = seq(from = 0, to = 11, by = 1)) +
labs(
x = 'Quantidade de Banheiros',
y = 'Densidade',
subtitle = '...seria possível um apartamento com um número tão grande de banheiros?'
)
# distribuição da variável quantidade de vagas
p4 <- ggplot(data = dados, mapping = aes(x = parkingSpaces)) +
geom_density(size = 0.3) +
geom_rug(size = 0.3) +
scale_x_continuous(breaks = seq(from = 0, to = 8, by = 1)) +
labs(
x = 'Quantidade de Vagas',
y = 'Densidade',
subtitle = '...que tipo de prédio teria tantas vagas de garagem disponíveis para um\núnico apartamento?'
)
# composição dos quatro plots
((p1 + p2) / (p3 + p4)) +
plot_annotation(title = 'As quatro variáveis abaixo apresentam um comportamento muito incomum dadas as suas características...',
tag_levels = 'a') &
theme(
plot.title = element_text(face = 'bold', size = 8),
plot.tag = element_text(size = 8),
text = element_text('Roboto')
)
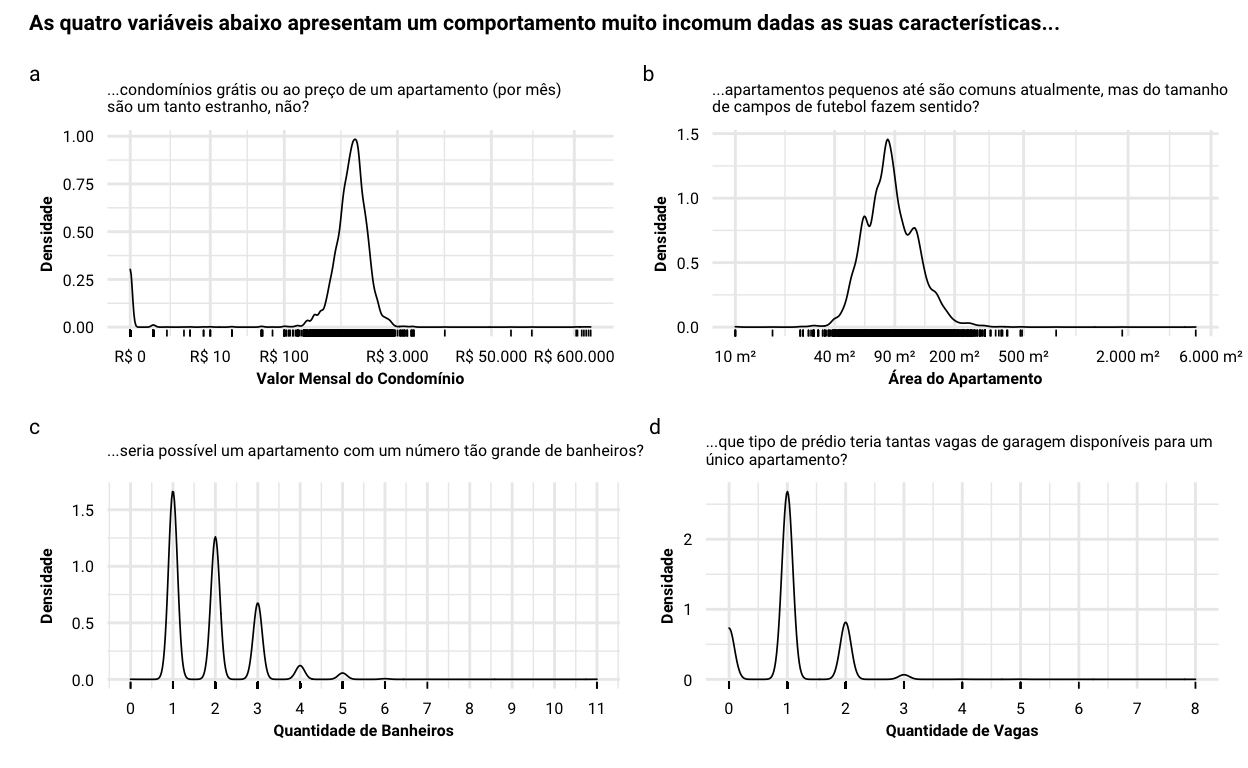
E, como não deixaria de faltar em toda análise exploratória, temos abaixo uma matriz com o coeficiente de correlação entre todas as variáveis preditoras numéricas. Eu decidi usar a correlação de Spearman, uma vez que acredito ser bem difícil que haja uma relação linear entre estas variáveis3. Como poderíamos esperar, muitas das correlações observadas não nos surpreendem.
Show code
library(corrr)
select(dados, where(is.numeric), -price, -latitude, -longitude) %>%
correlate(use = 'pairwise.complete.obs', method = 'spearman', diagonal = 1) %>%
stretch() %>%
ggplot(mapping = aes(x = x, y = y, fill = r)) +
geom_tile() +
geom_text(mapping = aes(label = round(x = r, digits = 2))) +
scale_fill_gradient(low = 'white', high = 'firebrick3') +
labs(
fill = 'Spearman (r)',
title = 'Correlação entre as variáveis preditoras numéricas'
) +
theme(
axis.title = element_blank(),
legend.position = 'none'
)
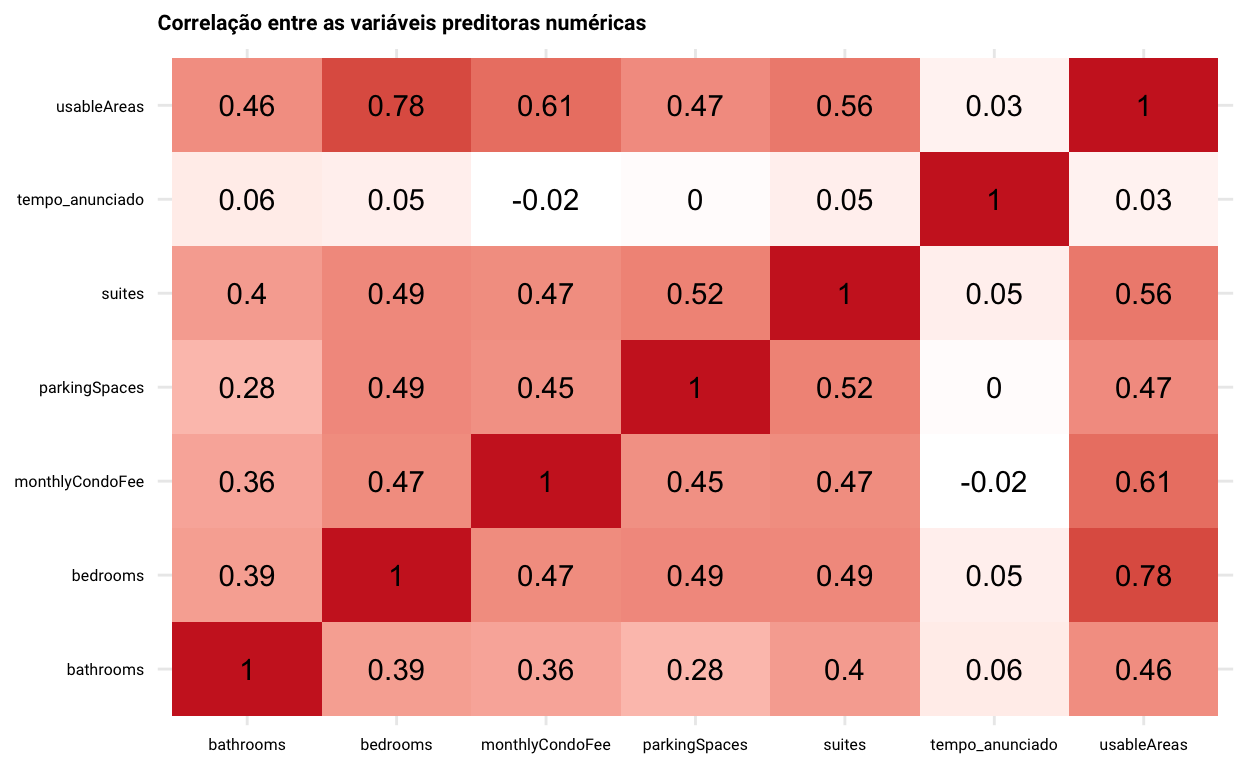
Modelagem
Vou começar esta parte fazendo uma copia dos dados originais e imputando NA nos valores estranhos daquelas quatro variáveis que falei ainda pouco.4
# copiando o dados
df <- dados
# removendo algumas colunas que não fazem sentido daqui para a frente - as três primeiras
# são identificadores de linha redundantes, enquanto os dois últimos têm muitos NAs e não
# terão uso. Vou remover o texto também pois não farei uso dele nesta postagem, e a Zona
# porque o efeito dela me parece estar muito confundido com o bairro
df <- select(df, -fonte, -json_data, -row_id, -full_text, -Zona, -latitude, -longitude)
# imputando NA para casos específicos em que há evidência de erro de imputação de informações
df <- df %>%
mutate(
# NA se o valor mensal do condominio for menor que R$ 50 ou maior que R$ 10K
monthlyCondoFee = ifelse(
test = between(x = monthlyCondoFee, left = 50, right = 10000),
yes = monthlyCondoFee,
no = NA
),
# NA se a área do apartamento foi maior que 500 m²
usableAreas = ifelse(test = usableAreas < 500, yes = usableAreas, no = NA),
# NA se houverem mais de 8 vagas de garagem
parkingSpaces = ifelse(test = parkingSpaces < 8, yes = parkingSpaces, no = NA),
# NA se houverem mais de 10 banheiro
bathrooms = ifelse(test = bathrooms < 10, yes = bathrooms, no = NA)
)
Com este ajuste dos dados feito5, a próxima coisa a se fazer é carregar o tidymodels e separar os dados de treino e teste.
library(tidymodels) # tudo relacionado à modelagem
# criando a divisão da base e estratificando através da variável resposta, a fim de garantir
# que os dados de treino e teste estarão cobrindo o mesmo intervalo de valores
set.seed(33) # reprodutibilidade
splits <- initial_split(data = df, prop = 0.8, strata = price)
# separando os dados divididos
df_train <- training(x = splits)
df_test <- testing(x = splits)
O treinamento de um algoritmo através do tidymodels (Kuhn and Wickham (2020)) pede que tenhamos os dados que serão utilizados para o treino, uma receita que descreva as etapas de pré-processamento que serão aplicadas aos dados em tempo de treino e uma instância do algoritmo. Todos estes três componentes são reunidos dentro de um workflow que cuidará então do ajuste do modelo. Assim, vou seguir essa lógica, e utilizar uma validação cruzada com 5 folds para treinar o algoritmo.
set.seed(42) # reprodutibilidade
# criando base com folds para o treino e validação do modelo
df_folds <- vfold_cv(data = df_train, v = 5, strata = price)
df_folds
# 5-fold cross-validation using stratification
# A tibble: 5 × 2
splits id
<list> <chr>
1 <split [7104/1780]> Fold1
2 <split [7108/1776]> Fold2
3 <split [7108/1776]> Fold3
4 <split [7108/1776]> Fold4
5 <split [7108/1776]> Fold5Vou criar uma receita para o pré-processamento dos dados que vai cuidar de algumas coisas. Primeiro, vou dizer que a coluna id representa o identificador único de cada linha. Na sequência, vou criar um passo para que qualquer nível das variáveis categóricas neighborhood (i.e., bairro) e Regiao (i.e., região administrativa) que ocorram na base de teste (ou fold de validação) e não ocorram na base (ou fold) de treino tenham um nível a parte para si próprias. Com esta etapa feita, vou tratar de agregar os níveis menos frequentes da variável neighborhood e, então, fazer um one-hot-encoding das duas variáveis categóricas utilizadas aqui - como pretendo usar um modelo de árvore, não há problema nisso. Com isto, parto para tratar daquela imputação de NAs que fiz, e utilizei um KNN para imputar os valores faltantes utilizando as informações da identidade do bairro, região administrativa, quantidade de quartos e suítes. Por fim, eu aplico uma transformação para logaritimizar os valores da variável resposta.
Têm dois pontos importantes que acho legal trazer aqui. O primeiro deles está na escolha das variáveis utilizadas para a imputação: considerei aqui a premissa de que o valor médio das quatro variáveis que seriam imputadas variam em função da identidade do bairro e da região administrativa e que, além disso, mesmo dentro destes àquelas variáveis também poderiam mudar em função da quantidade de quartos e suítes. O segundo ponto é que a receita definida abaixo é apenas uma instância do pré-processamento que deve ser aplicado aos dados antes de passá-los ao algoritmo. Com isto, esta receita será aplicada aos dados (ou folds) de treino em tempo de ajuste do algoritmo, e não no momento que o objeto pre_processamento é criado - prevenindo assim que haja algum tipo de vazamento dos dados de teste para os de treino.
pre_processamento <- recipe(price ~ ., data = df_train) %>%
# dizendo para o pré-processamento que a coluna id é o identificador de cada linha
update_role(id, new_role = 'id') %>%
# criando niveis novos para as variaveis bairro e regiao administrativa caso um nivel
# que nao tenha sido usado no treinamento apareça
step_novel(neighborhood, Regiao) %>%
# agrupando niveis da variavel bairro que são muito infrequentes
step_other(neighborhood, threshold = 0.01, other = 'Outros') %>%
# fazendo um one hot encoding das variaveis de bairro e regiao
step_dummy(neighborhood, Regiao, one_hot = TRUE) %>%
# usando um KNN para imputar as informações faltantes nas quatro variaveis problematicas
step_impute_knn(monthlyCondoFee, usableAreas, parkingSpaces, bathrooms,
impute_with = imp_vars(contains('neighborhood'), contains('Regiao'),
'bedrooms', 'suites', -ends_with('new')),
) %>%
# logaritimizando a variável resposta
step_log(price)
O próximo passo será criar uma instância do algoritmo que será usado. No caso, vou utilizar o algoritmo xgboost (Chen and Guestrin (2016)), dada a boa performance que este tipo de algoritmo normalmente entrega nos problemas de dados. Vou utlizar o early stopping, a fim de reduzir a chance de que haja algum tipo de problema de sobre-ajuste do algoritmo aos dados. Finalmente, deixarei os valores de alguns hiperparâmetros do algoritmo serem definidos através de uma otimização bayesiana.
library(xgboost) # carregando o xgboost
# criando uma instancia do xgboost
xgb_instance <- boost_tree(
trees = 1000, # quantidade de árvores
tree_depth = tune(), # profundidade das árvore
mtry = tune(), # quantidade de variáveis disponíveis
sample_size = tune(), # proporção da amostra a ser usada
learn_rate = tune(), # taxa de aprendizado
stop_iter = 100
) %>%
set_engine(engine = 'xgboost') %>%
set_mode(mode = 'regression')
Pronto, agora temos os três principais ingredientes para criarmos um workflow de ajuste dos dados.
xgb_wf <- workflow() %>%
add_recipe(pre_processamento) %>%
add_model(xgb_instance)
Hora de ajustar o modelo! Para isso, vou utilizar uma otimização bayesiana para determinar os valores dos hiperparâmetros que fornecem o menor erro de previsão. A ideia geral da otimização bayesiana é que ela usa as informações dos valores dos hiperparâmetros e a respectiva performance obtida em cada iteração para treinar um meta-modelo que indicará qual a combinação de hiperparâmetros têm a expectativa de melhorar a sua performance e que, portanto, deverá ser utilizada na iteração seguinte. De uma forma geral, podemos pensar nesta otimização como uma busca mais inteligente pela melhor combinação de hiperparâmetros. Finalmente, um ponto importante aqui é que quero que o modelo gerado nos entregue uma previsão com baixo erro; portanto, utilizarei a raíz quadrada dos erros quadráticos médios (RMSE, Root Mean Squared Error) como a métrica de avaliação da performance do modelo.
# finalizando a seleção dos hipeparametros que serão testados
xgb_parameters <- parameters(xgb_instance) %>%
update(mtry = mtry(range = c(1L, 10L)))
# definindo a métrica que quero otimizar
metrica <- metric_set(rmse)
# buscando melhor combinação de hiperparametros através de uma busca bayesiana
set.seed(42) # reprodutibilidade
xgb_bayes <- xgb_wf %>%
tune_bayes(
# dados com os folds de treino
resamples = df_folds,
# espaço de hiperparametros que serão otimizados
param_info = xgb_parameters,
# define quantas combinações de hiperparametros-performance serão geradas antes do algoritmo
# de otimização bayesiana começar a gerar as combinações que serão de fato testadas
initial = 10,
# quantidade de interações da otimização bayesiana
iter = 100,
# conjunto de metricas que serão avalidadas
metrics = metrica,
objective = exp_improve(),
# argumentos de controle da função
control = control_bayes(no_improve = 20, uncertain = 4, seed = 33,
save_pred = TRUE, verbose = FALSE)
)
Yay! Modelo ajustado! Agora, vamos avaliá-lo e tentar entendê-lo!
Validação do Modelo
Vou começar olhando como ficaram os resultados da busca pela melhor combinação de hiperparâmetros através da otimização bayesiana. A figura abaixo demonstra de que forma a performance do modelo (avaliada através do RMSE) variou em função dos valores de cada hiperparâmetro utilizado durante o processo. Fica muito claro que muito da variação na performance do modelo depende do valor da taxa de aprendizado utilizada, enquanto os demais hiperparâmetros parecem ter um impacto bem menos claro.
autoplot(object = xgb_bayes) +
labs(
y = 'RMSE',
x = 'Valor do Hiperparâmetro',
title = 'Impacto dos hiperparâmetros sobre a performance do modelo',
subtitle = 'A variação na taxa de aprendizado parece ter o maior impacto sobre a variação na performance do modelo'
)
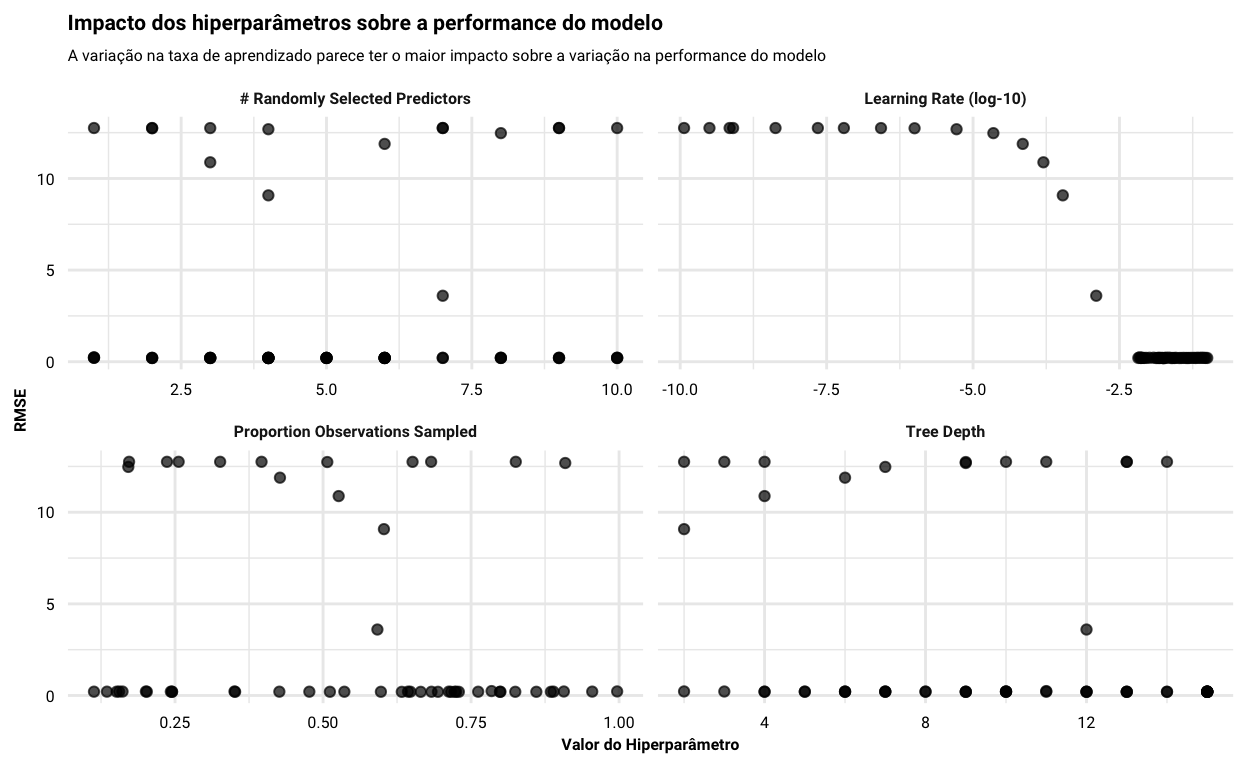
A tabela abaixo ilustra bastante este ponto: os cinco modelos com melhor performance têm taxas de aprendizado bastante próximos e valores de RMSE quase que idênticos, ainda que os valores dos outros hiperparâmetros tenham variado bem mais.
show_best(x = xgb_bayes)
# A tibble: 5 × 11
mtry tree_depth learn_rate sample_size .metric .estimator mean
<int> <int> <dbl> <dbl> <chr> <chr> <dbl>
1 4 15 0.0180 0.716 rmse standard 0.199
2 4 13 0.0188 0.633 rmse standard 0.200
3 3 15 0.0244 0.799 rmse standard 0.200
4 9 9 0.0173 0.665 rmse standard 0.200
5 6 14 0.0153 0.351 rmse standard 0.200
# … with 4 more variables: n <int>, std_err <dbl>, .config <chr>,
# .iter <int>Mas beleza…temos um modelo treinado e otimizado…mas será que ele é bom mesmo? Em outras palavras, será que a taxa de erro que obtivemos é aceitável? Um ponto importante que nos ajuda a responder àquela pergunta, e que acabei pulando no início do processo, é a definição dos baselines para o problema que estamos buscando resolver. Isto é importante pois ela ajuda a estabelecer um nível de controle a partir do qual podemos dizer se aquilo que estamos implementando está de fato trazendo algum ganho para a resolução do problema. Na prática, podemos pensar que a definição deste nível nos ajuda a responder questões como ‘Eu preciso usar machine learning para resolver este problema?’ e ‘A otimização de hiperparâmetros foi eficaz para melhorar a performance do modelo?’.
Tomando como ponto de partida a pergunta de se precisávamos mesmo de um modelo de machine learning, vou definir como um baseline para a previsão seria uma regra de negócio através da qual preveríamos que o valor do apartamento corresponde ao valor da média de preço. Nesse contexto, esperamos que um modelo de machine learning útil (ou com boa performance) seria aquele que supera esta simples regra de negócio - caso o modelo tivesse uma taxa de erro maior do que a regra de negócio, então não precisaríamos de um modelo, certo? Para implementar este modelo naive, calcularei o valor da média do preço do apartamento dentro de cada fold de treino e utilizar este valor para calcular o RMSE dentro de cada fold de validação; por fim, calcularei o valor médio e do erro padrão do RMSE calculado desta forma, a fim de garantir que estaremos comparando as duas estratégias de modelagem em cima dos mesmos dados, variando apenas a forma como a previsão é gerada (i.e., modelo vs ‘não’ modelo).
# calculando o RMSE que seria obtido entre todos os folds utilizando como modelo apenas o
# valor medio do preco do apartamento
modelo_naive <- df_folds %>%
mutate(
# pegando o dataframe de treino de cada fold
train_fold = map(.x = splits, .f = analysis),
# pegando o dataframe de validação de cada fold
val_fold = map(.x = splits, .f = assessment),
# calculando o valor do preco medio do apartamento de cada fold de treino
preco_medio_fold = map_dbl(.x = train_fold, .f = ~ mean(.x$price)),
# extraindo os valores do preco medio de cada fold de validação
preco_fold_val = map(.x = val_fold, .f = ~ .x %>% pull(price))
) %>%
# pegando so as colunas de id do fold, medio do preco no fold de treino e preco observado
# no fold de validacao
select(id, preco_medio_fold, preco_fold_val) %>%
# desaninhando a list-column do preco vindo do fold de validação
unnest(preco_fold_val) %>%
# agrupamento o dataframe pelo id do fold
group_by(id) %>%
# calculando o RMSE para cada fold individualmente - logaritimizando as duas colunas para
# que os valores obtidos sejam comparáveis com aqueles dados pelo modelo dado o pre-processamento
summarise(rmse = rmse_vec(truth = log(preco_fold_val), estimate = log(preco_medio_fold))) %>%
# calculando o valor do rmse medio entre os folds e o desvio padrao
summarise(mean = mean(rmse), std_err = sd(rmse))
O segundo baseline que quero definir é um que nos diga se a otimização de hiperparâmetros está trazendo algum ganho para o nosso problema de negócio. Para tal, vou ajustar um XGBoost utilizando a configuração default de hiperparâmetros aos mesmos folds de treino e validação. Com isso, temos também um resultado que nos permita comparar o impacto da otimização de hiperparâmetros frente a um cenário em que tudo menos isto foi feito.
# ajustando o xgboost sem fazer nenhum tipo de melhoria ao modelo
## instanciando o algoritmo com as configurações default
xgb_default <- boost_tree() %>%
set_engine(engine = 'xgboost') %>%
set_mode(mode = 'regression')
## ajustando o xgboost com configuracao default de hiperparametros aos dados dos folds
set.seed(99) # reprodutibilidade
xgb_baseline <- workflow() %>%
# adicionando o mesmo pre-processamento
add_recipe(pre_processamento) %>%
# instanciando o algoritmo default
add_model(xgb_default) %>%
# usando o fit resamples para realizar o ajuste em cima da validação cruzada
fit_resamples(
resamples = df_folds,
metrics = metrica,
control = control_resamples(verbose = FALSE, allow_par = TRUE, save_pred = TRUE)
)
Pronto, agora finalmente podemos definir se o erro obtido com o modelo otimizado é aceitável ou não. Os resultados deste teste são apresentados na figura abaixo, que demonstra que (1) o erro obtido com o modelo supera e muito aquele do modelo naive (i.e., faz sentido usar um modelo de machine para endereçar este problema de negócio) e (2) o erro obtido com a otimização de hiperparâmetros é menor do que aquele observado com a sua configuração default (i.e., a otimização de hiperparâmetros traz um ganho real de performance). Ou seja, a performance obtida com o modelo otimizado parece ser boa sim.
Show code
# juntando os resultados das três estratégias em uma tibble
bind_rows('XGBoost Otimizado' = select(.data = show_best(x = xgb_bayes, n = 1), mean, std_err),
'XGBoost Default' = select(.data = collect_metrics(x = xgb_baseline), mean, std_err),
'Modelo Naive' = modelo_naive,
.id = 'estrategia') %>%
# reordenando os niveis das estrategias
mutate(estrategia = fct_relevel(.f = estrategia, 'Modelo Naive', 'XGBoost Default')) %>%
# plotando o valor medio e do intervalo de confiança de 95% do RMSE para cada estrategia
ggplot(mapping = aes(x = estrategia, y = mean, fill = estrategia)) +
geom_errorbar(mapping = aes(ymin = mean - 1.96 * std_err, ymax = mean + 1.96 * std_err), width = 0.1) +
geom_point(size = 3, shape = 21, show.legend = FALSE) +
geom_text(mapping = aes(label = paste0(round(x = mean, digits = 3), ' ± ', round(x = 1.96 * std_err, digits = 3))),
nudge_y = 0.03, fontface = 'bold') +
scale_fill_manual(values = c('white', 'dodgerblue3', 'indianred3')) +
labs(
title = 'Comparação entre estratégias de previsão',
subtitle = 'Um modelo de Machine Learning e a otimização de hiperparâmetros ajudam a resolver este problema de dados',
x = 'Estratégia de Previsão',
y = 'RMSE',
caption = 'Os círculos representam o valor médio do RMSE, enquanto que as barras representam o intervalo de confiança de 95%.'
) +
theme(
plot.title = element_text(face = 'bold', size = 12),
plot.subtitle = element_text(size = 10),
axis.title = element_text(face = 'bold', size = 10),
axis.text = element_text(color = 'black', size = 10),
strip.text = element_text(face = 'bold', size = 10)
)
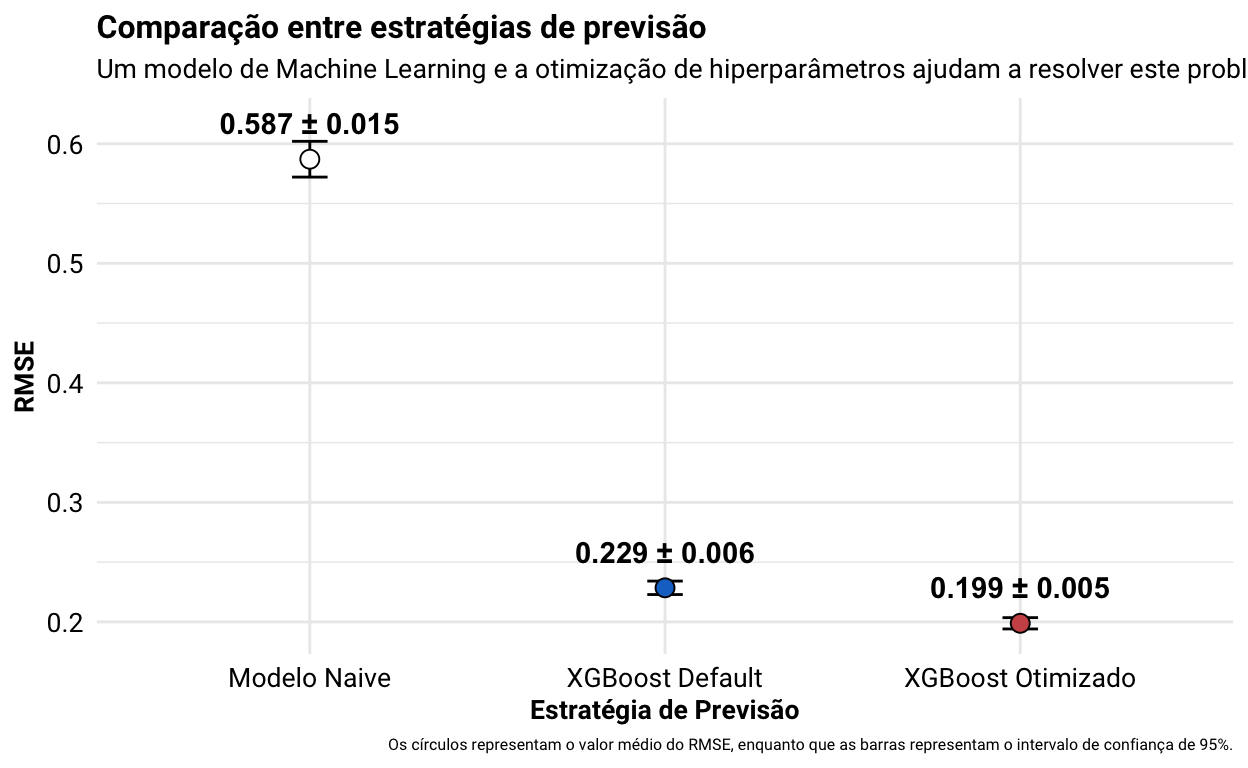
Uma vez que sabemos que o modelo gerado tem algum valor, faz sentido então olhar de que forma ele performou na base de teste. Vou finalizar o workflow com a melhor combinação de hiperparâmetros encontrados durante a otimização bayesiana, ajustar o algoritmo uma última vez a todos os dados da base de treino e avaliá-lo na base de teste. Como podemos ver abaixo, a performance do modelo na base de teste foi bastante parecida com aquela obtida durante a validação cruzada, indicando que o nosso modelo está bem ajustado aos dados.
# concluindo o workflow do xgboost
wf_final <- xgb_wf %>%
# utilizando a melhor combinação de hiperparametros da otimização bayesiana
finalize_workflow(parameters = select_best(x = xgb_bayes))
# treinando o xgboost uma ultima vez para avaliar a performance na base de teste
set.seed(42) # reprodutibilidade
xgb_final <- wf_final %>%
# usando o last fit para ajustar o algoritmo na base de treino e escorar na base de teste
last_fit(split = splits, metrics = metrica)
# performance na base de teste
xgb_final %>%
collect_metrics()
# A tibble: 1 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 rmse standard 0.199 Preprocessor1_Model1Finalmente, é importante examinarmos também se os valores previstos estão reproduzindo bem aqueles observados ou se existe algum tipo de viés de previsão no modelo. Para isso, extrairei as previsões feitas pelo modelo tanto na base de treino quanto na base de teste, e calcular os seus resíduos (i.e., a diferença entre o valor previsto e o observado). Vou buscar três coisas com isto:
- Se observarmos a relação entre os valores previstos e os valores observados, eles devem seguir uma relação quase de 1:1. Desvios desta linha podem indicar, por exemplo, que o modelo não está conseguindo reproduzir bem os valores observados para um recorte específico dos dados e, portanto, põem em dúvida a validade do modelo;
- Também é legal avaliarmos se a distribuição dos resíduos está próxima daquela esperada para uma distribuição normal padrão. Apesar do modelo utilizado não assumir nada com relação à distribuição de normalidade dos resíduos, acho interessante dar uma olhada nisso, a fim de também definirmos se existe algum tipo de viés nas previsões geradas;
- Por fim, também vou verificar se existe uma diferença nestes padrões entre a base de treino e a de teste. Caso isto ocorra, pode ser um sinal de que existe algum tipo de sobre-ajuste do modelo aos dados, por exemplo.
Show code
# pre-processando os dados de treino utilizando a receita treinada
train_baked <- bake(
# vamos extrair a receita treinada do modelo que ajustamos e usá-la para gerar os dados pre-processados
object = extract_recipe(x = xgb_final),
new_data = df_train
) %>%
# removendo as variaveis que nao precisamos
select(-id, -price) %>%
# passando para matriz de forma que o xgboost possa usa-la
as.matrix()
# gerando previsoes na base de treino
previsoes_treino <- predict(
# para fazer a previsão precisamos extrair o atributo fit do modelo parsnip
object = extract_fit_parsnip(x = xgb_final),
# como new_data precisamos passar os dados já preprocessdos
new_data = train_baked
)
# juntando as previsões na base de teste e treino
previsoes <- xgb_final %>%
collect_predictions() %>%
# substituindo o id por um indicador de que estas são as previsões da base de teste
mutate(id = 'Base de Teste') %>%
# pegando só as colunas que me serão úteis para a criação da figura
select(id, .pred, price) %>%
# juntando as previsões vindas da base de treino
bind_rows(df_train %>%
# pegando só a coluna do preço observado
select(price) %>%
# adicionando as previsões que fiz ali em cima (a ordem das linhas é a mesma)
mutate(previsoes_treino,
# logaritimizando o preco para que a comparação seja na mesma escala
price = log(price),
# criando um id para as previsões da base de treino
id = 'Base de Treino')) %>%
mutate(
# reordenando os níveis de id
id = fct_relevel(.f = id, 'Base de Treino'),
# calculando os residuos do modelo
residuo = .pred - price
)
# valores previstos vs obserados
p1 <- ggplot(data = previsoes, mapping = aes(x = .pred, y = price)) +
facet_wrap(~ id) +
geom_point(color = 'grey70', shape = 16, alpha = 0.3, size = 0.5) +
geom_abline(slope = 1, intercept = 0, color = 'dodgerblue3', size = 0.5) +
labs(
title = 'Relação entre os valores previstos e observados para cada uma das bases',
subtitle = 'A linha azul representa uma relação 1:1 entre os valores previstos e observados',
x = 'Valor Previsto',
y = 'Valor Observado'
)
# histograma de distribuição dos resíduos
p2 <- ggplot(data = previsoes, mapping = aes(x = residuo)) +
facet_wrap(~ id, scales = 'free_y') +
geom_histogram(color = 'black', fill = 'grey80', bins = 30, stat = 'bin', size = 0.3) +
geom_rug(size = 0.3) +
labs(
title = 'Distribuição dos resíduos do modelo para cada uma das bases',
subtitle = 'A distribuição dos resíduos parece muito próxima daquela da distribuição normal',
x = 'Resíduo (Previsão - Observado)',
y = 'Densidade'
)
# compondo a figura
p1 / p2

O diagnóstico visual das previsões e do resíduo do modelo parecem OK! Hora de entender e usar o modelo então!
Entendimento do Modelo
Vou utilizar o pacote fastshap (Greenwell (2020)) para nos ajudar a ter alguma ideia de que tipo de padrões o modelo aprendeu e de que forma isto está relacionado às previsões feitas. Começamos calculando os valores de SHAP (Lundberg and Lee (2017)) para cada linha na nossa base de dados - isto é, definimos a contribuição do valor de cada variável preditora para a previsão feita em cada uma das instâncias.
library(fastshap) # para extrair os valores de shap do modelo
# criando função para encapsular geração da previsao
gera_previsao <- function(object, newdata) {
predict.model_fit(object, new_data = newdata)$.pred
}
# gerando valores de shap para cada instancia
shap <- explain(
object = extract_fit_parsnip(x = xgb_final),
X = train_baked, pred_wrapper = gera_previsao
)
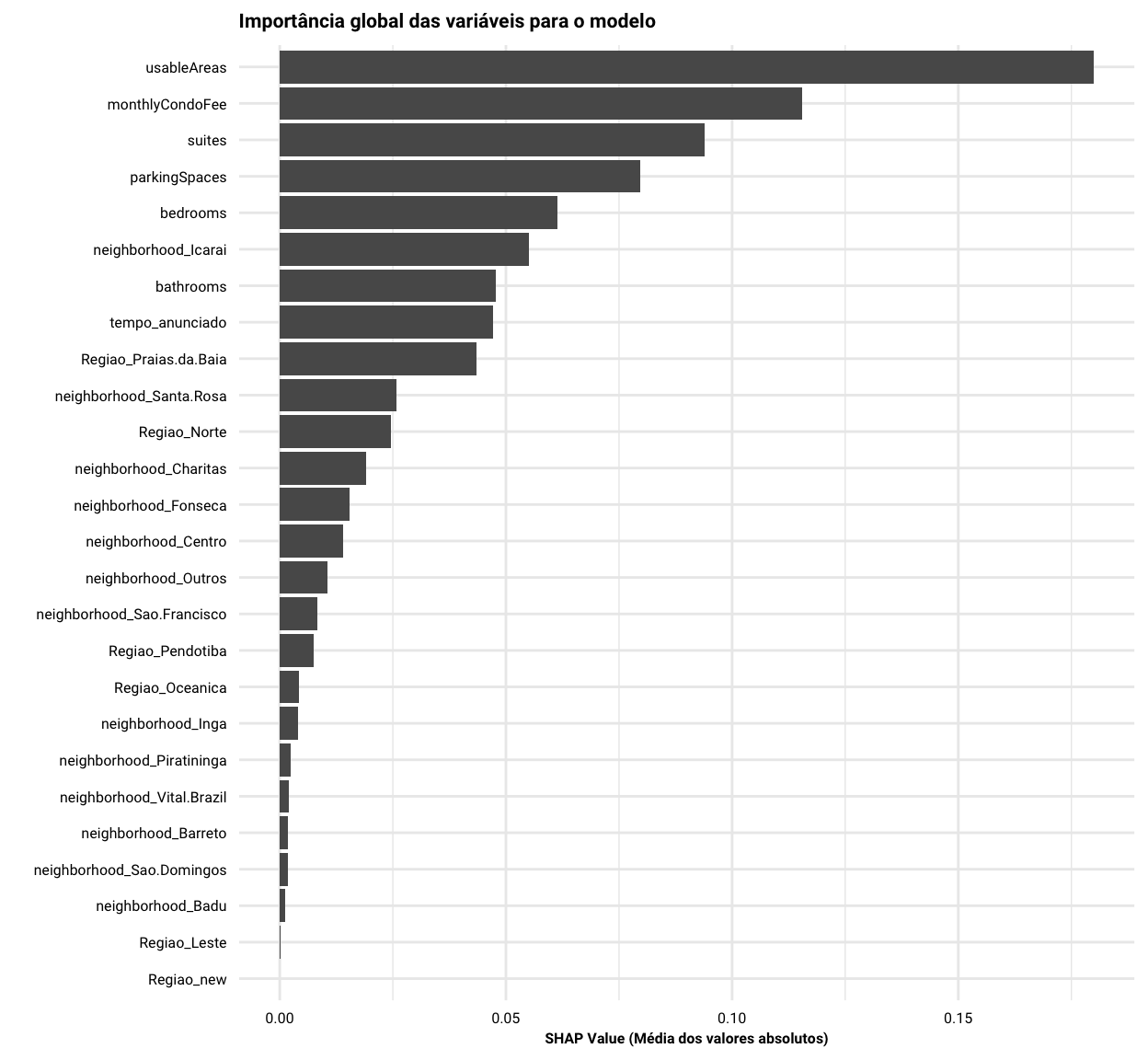
O primeiro insight que vamos buscar é a importância global das variáveis utilizadas para o modelo, o que é obtido através da média dos valores absolutos de SHAP para cada uma das variáveis no modelo. Sem muita surpresa, a figura a seguir mostra que o valor do condomínio e a área do apartamento têm uma contribuição bastante grande para determinar o preço do imóvel. Outras variáveis como a quantidade de suítes, quartos e vagas na garagem também tiveram uma importância considerável, enquanto as dummies utilizadas para alguns bairros parecem não ter tido tanta importância assim.
Show code
A próxima figura traz um outro olhar sobre a importância das variáveis para o modelo e a forma pela qual elas contribuem para chegarmos na previsão do preço do apartamento6. Assim como na figura anterior, as variáveis estão ordenadas de cima para baixo em termos de importância para a previsão. No entanto, temos agora mais algumas informações:
- Os círculos agora representam a variação nos valores de SHAP para cada instância dentro de cada variável - e.g. os valores de SHAP para a variável usableAreas entre todas as instâncias na base de treino vai de algo como -1 à 1;
- A variação nos valores de SHAP do lado negativo para o lado positivo está associado à variação no preço de imóvel: quando o valor de SHAP é negativo, isto quer dizer que o valor daquela variável para àquela instância contribui para uma queda no preço do apartamento; por outro lado, quando o valor de SHAP é positivo, então o valor da variável para àquela instância contribui para que o preço do apartamento aumente;
- A escala de cor ilustra de que forma a variação nos valores da variável, de seu valor mínimo ao seu valor máximo, estão associadas à variação nos valores de SHAP e, consequentemente, ao preço do apartamento. Ou seja, a escala de cor nos dá uma ideia gera da direção da relação entre cada variável e o preço do apartamento. Por exemplo, a variável bedrooms vai do azul ao vermelho conforme os valores de SHAP vão do lado negativo para o lado positivo. Isto indica que quanto maior a quantidade de quartos no apartamento maior o valor de SHAP e, consequente, maior o valor do apartamento - logo, existe uma relação positiva entre a quantidade de quartos e o valor do apartamento. Quando pensamos em uma dummy - uma variável que assume o valor 0 (i.e., não) ou 1 (i.e., sim) o tipo de interpretação é bastante parecido: quando o valor da variável Regiao_Praias.da.Baia é 0 (i.e., o seu valor mínimo) os valores de SHAP são negativo, enquanto quando ela é 1 (i.e., o seu valor máximo) os valores de SHAP são positivos. Ou seja, o preço do apartamento é maior quando um apartamento está situado na região administrativa Praias da Baia (i.e., valor da dummy é 1), e cai quando o imóvel não está situado ali (i.e., valor da dummy é 0).
Show code
# valores de cada uma das variaveis
valores_variaveis <- train_baked %>%
# passando os dados para um tibble
as_tibble %>%
# adicionando um identificador sequencial para a linha
rownames_to_column(var = 'row_id') %>%
# passando a tabela para o formato longo
pivot_longer(cols = monthlyCondoFee:Regiao_new, names_to = 'variavel', values_to = 'valor')
# criando figura do shap discriminando não só a magnitude do impacto bem como a direção do
# impacto de cada variável sobre a previsão
shap %>%
# passando a tabela do shap para uma tibble
as_tibble %>%
# adicionando um identificador sequencial para a linha
rownames_to_column(var = 'row_id') %>%
# passando a tabela para o formato longo
pivot_longer(cols = monthlyCondoFee:Regiao_new, names_to = 'variavel', values_to = 'shap_value') %>%
# juntando com os valores observados
left_join(y = valores_variaveis, by = c('row_id', 'variavel')) %>%
# reordenando as variáveis através da importância do shap (media dos valores absolutos)
mutate(
variavel = fct_reorder(.f = variavel, .x = shap_value, .fun = function(x) mean(abs(x)))
) %>%
# agrupando os valores por variavel
group_by(variavel) %>%
# criando um mapa de cores através do qual rankearemos os valores observados de cada variavel
mutate(
# criando o rank para cada uma das variaveis
color_map = rank(x = valor, ties.method = 'min'),
# padronizando o rank dentro de cada variavel, caso contrário o mapa de cores vai ficar confundido
# com quantos níveis de rank cada variável tem
color_map = (color_map - min(color_map)) / (max(color_map) - min(color_map))
) %>%
# plotando a magnitude da contribuição e direção do impacto de cada variável
ggplot(mapping = aes(x = shap_value, y = variavel, color = color_map)) +
geom_vline(xintercept = 0, linetype = 2, color = 'black') +
geom_point(position = position_jitter(height = 0.1), alpha = 0.5, size = 1) +
scale_color_gradient(low = 'dodgerblue1', high = 'indianred1',
breaks = c(0, 1), labels = c('Min', 'Max')) +
labs(
x = 'SHAP Value',
color = 'Valor da\nVariável',
title = 'Contribuição e efeito das variáveis sobre a previsão',
subtitle = 'O valor do apartamento aumenta quanto maior for o SHAP value para uma observação, enquanto que a variação\nno valor original de uma variável de seu mínimo ao seu máximo ao longo deste gradiente indica se ela possui uma\nrelação positiva ou negativa com o valor do imóvel.'
) +
theme(
axis.title.y = element_blank(),
legend.title = element_text(size = 8, face = 'bold', vjust = 3),
legend.key.width = unit(x = 0.5, units = 'cm'),
legend.key.height = unit(x = 0.5, units = 'cm')
)

Os padrões que são observados aqui são bastante consistentes com o que se espera da relação dessas variáveis com o valor de um apartamento, assim como com o que conheço sobre o município de Niterói. Logo, acredito que este seja um modelo bastante válido para fazermos previsões e endereçar as perguntas originais que motivaram este post.
Conclusões
Desenvolvi aqui um modelo de machine learning com o intuito de me ajudar com duas perguntas: (1) ‘quanto vale o apartamento em que moro?’ e ‘como saber se um apartamento está anunciado a um preço razoável?’. Depois de todo os desenvolvimento, validação e entendimento do modelo, acho que cheguei à uma ferramenta que pode me dar um caminho razoável. Então vamos lá.
Vou considerar aqui o tipo de apartamento em que moro…por quanto ele deveria ser anunciado de acordo com o modelo desenvolvido?
# criando um apartamento teorico - usando as mesmas colunas que tínhamos na base original
apto_teorico <- tibble(id = 'teorico', price = NA, monthlyCondoFee = 800,
tempo_anunciado = 1, usableAreas = 60, parkingSpaces = 1,
suites = 1, bathrooms = 2, bedrooms = 2, neighborhood = 'Inga',
Regiao = 'Praias da Baia')
# extraindo a previsao do valor do meu apto teorico
predict(
# utilizando o fit do modelo ajustado
object = extract_fit_parsnip(x = xgb_final),
# preprocessando os dados do apartamento teorico com a receita treinada
new_data = bake(
object = extract_recipe(x = xgb_final),
new_data = apto_teorico) %>%
select(-price, -id) %>%
as.matrix()
) %>%
# extraindo apenas a previsão
pull(.pred) %>%
# colocando ela de volta na escala real
exp %>%
# estilizando o output
scales::dollar(x = ., prefix = 'R$ ', big.mark = '.', decimal.mark = ',', accuracy = 0.01)
[1] "R$ 461.745,19"Acho que essa estimativa é bem OK. Na realidade, uma pessoa corretora acabou avaliando o apartamento no meio do caminho, e chegou a um valor bem parecido com esse. Então acho que tá bem consistente mesmo.
Beleza…e se eu quisesse usar esse mesmo modelo para me ajudar a buscar o apartamento ideal? Para isso, vou gerar a previsão do preço do apartamento para todos os anúncios na base de dados e vou calcular os resíduos (i.e., a diferença entre o preço previsto e o preço observado). Os apartamentos que seriam os ideais seriam aqueles nos quais o modelo está prevendo um preço maior do que o observado ou, em outras palavras, aqueles nos quais os resíduos são os maiores possíveis. Portanto, vou aplicar um filtro aqui para identificar alguns apartamentos que têm aquilo que estou buscando e, a partir deles, vou extrair os 10 apartamentos que estão mais subvalorizados de acordo com o modelo.
Show code
# pre-processando todos os dados disponíveis
all_baked <- bake(
# vamos extrair a receita treinada do modelo que ajustamos e usá-la para gerar os dados pre-processados
object = extract_recipe(x = xgb_final),
new_data = df
) %>%
# removendo as variaveis que nao precisamos
select(-id, -price) %>%
# passando para matriz de forma que o xgboost possa usa-la
as.matrix()
# gerando previsoes para todos os dados disponiveis
previsoes_gerais <- predict(
object = extract_fit_parsnip(x = xgb_final),
new_data = all_baked
)
# identificando os 10 apartamentos que estão abaixo do valor previsto pelo modelo
df %>%
mutate(
# adicionando as previsõs do modelo
previsoes_gerais,
# colocando as previsões na escala original
.pred = exp(.pred),
# calculando o resíduo na escala original
residuo = .pred - price
) %>%
# impondo algumas restrições ao apartamento que busco: deve ser nos bairros de São Francisco
# ou Charitas, possuir no mínimo uma suíte e mais de 2 quartos
filter(neighborhood %in% c('Sao Francisco', 'Charitas'), bedrooms > 2, suites > 0) %>%
# pegando os 10 apartamentos com o maior residuo, i.e. onde o valor predito pelo modelo é maior
# do que o valor anunciado
slice_max(n = 10, order_by = residuo) %>%
# organizando a tabela
select(-Regiao) %>%
relocate(.pred, residuo, .after = price) %>%
# plotando a tabela
reactable(striped = TRUE, highlight = TRUE, compact = TRUE, showSortable = TRUE,
style = list(fontSize = "10px"),
defaultColDef = colDef(align = 'center'),
columns = list(
price = colDef(name = 'Preço anunciado', format = colFormat(currency = 'BRL', separators = TRUE, locales = 'pt-BR')),
.pred = colDef(name = 'Preço previsto', format = colFormat(currency = 'BRL', separators = TRUE, locales = 'pt-BR')),
residuo = colDef(name = 'Resíduo', format = colFormat(currency = 'BRL', separators = TRUE, locales = 'pt-BR')),
monthlyCondoFee = colDef(name = 'Condomínio', format = colFormat(currency = 'BRL', separators = TRUE, locales = 'pt-BR')),
tempo_anunciado = colDef(name = 'Tempo anunciado'),
usableAreas = colDef(name = 'Área', format = colFormat(suffix = 'm²')),
parkingSpaces = colDef(name = 'Vagas'),
suites = colDef(name = 'Suítes'),
bathrooms = colDef(name = 'Banheiros'),
bedrooms = colDef(name = 'Quartos'),
neighborhood = colDef(name = 'Bairro')
)
)
Sucesso, não? Se quiser ver que apartamentos são esses dos anúncios, basta juntar o número na coluna id com um dos dois links, www.zapimoveis.com.br/imovel/id-<numero_do_id>/ (funciona na maior parte dos casos) ou www.zapimoveis.com.br/lancamento/id-<numero_do_id> (quanto é um apartamento na planta ou em construção), e explorar o anúncio. Todos os apartamentos que apareceram nesse Top 10 aqui são interessantes…só falta mesmo é o dinheiro para poder comprar!
Possíveis Extensões
- Utilizamos os intervalos padrão de cada hiperparâmetros para executar a otimização bayesiana. Neste caso, poderíamos utilizar os resultados obtidos aqui para focar em uma região do espaço de hiperparâmetros específico, a fim de tentar obter um modelo ainda melhor;
- Como falei no início do post, decidi começar simples e não usei a variável de texto de descrição do anúncio. Eu encontrei esse post aqui, onde a Julia Silge trabalha o mesmo tipo de problema usando texto, e achei bastante legal para tentar depois;
- Outro ponto importante é que a base de dados possui muitas outras variáveis que não apresentei aqui, tais como pontos de interesse próximos a cada apartamento e informação do CEP de cada apartamento. Também seria interessante utilizar esse tipo de informação aqui;
- Eu foquei em anúncios de apartamento aqui, mas nada impede de expandir esta solução para qualquer outro tipo de imóvel neste ou em outro município - basta raspar os dados do site;
- Enquanto expandir o escopo da solução é uma possibilidade, o contrário também se faz válido (especialmente pela enorme quantidade de anúncios para alguns bairros em específico). A vantagem de se ter modelos específicos para cada bairro está no potencial de chegarmos a um modelo mais preciso para àquela realidade específica;
- É possível utilizar estes mesmos dados para tentar endereçar outros tipos de problema. Poderíamos utilizar, por exemplo, os dados da descrição do apartamento para tentar prever em que bairro ele fica. Acho essa possibilidade bem interessante, e de repente acabarei abordando ela de alguma forma no futuro.
Shapefile obtido a partir de https://geo.niteroi.rj.gov.br/civitasgeoportal/↩︎
Não mostro aqui mas, de fato, a relação entre muitas delas não é linear.↩︎
Dei uma lida no texto de descrição dos anúncios e parece que todos os casos que narrei aqui são erros de imputação de informação mesmo. Assim, acredito que esta solução não seja um problema.↩︎
Se você for uma pessoa curiosa, eu acabei imputando um
NAa 583 linhas da base↩︎Não existe uma função no
fastshappara criar essa figura, então tentei emular uma figura similar que existente dentro do pacoteshap.↩︎